VQ-VAE + Diffusion + Masking

Abstract
Diffusion + VQ-VAE + Masking.
확산으로 벡터 양자화에 의한 오차의 누적을 피하고 이미지 해상도에 따라 선형적으로 비용이 증가하는 선형 회귀 방법(AR)과 달리 엄청 빠르면서도 더 나은 품질을 보여준다.
Introduction
DALL-E와 같은 AR 방식의 단점
- 왼쪽 위에서 오른쪽 아래로 순차적으로 예측되기 때문에 편향 생김
- 추론 단계가 이전에 샘플링된 토큰을 기반으로 실행되기 때문에 앞선 토큰의 오차가 계속 누적되어 전파됨
따라서 확산 모델을 사용. 또한 네트워크 수렴을 위해 mask-and-replace 전략 사용.
Background: Learning Discrete Latent Space of Images Via VQ-VAE

VQ-VAE는 인코더 E, 디코더 G, 코드북 Z(i ∈ {1, 2, ..., K})로 구성된다.
이미지 x가 주어지면 공간 feature zij를 가까운 코드북 항목 zk에 매핑하는 quantizer Q(·)와 컬렉션 zq를 얻는다.
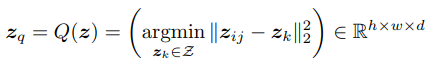
x̃ = G(zq). 따라서 이미지 합성은 잠재 분포에서 이미지 토큰을 샘플링하는 것과 같다. 모델은 다음과 같이 훈련될 수 있음.

첫째 항부터 순서대로 전체 과정 최적화, 코드북 최적화, 인코더 최적화.
코드북 매핑은 역전파가 불가능하기 때문에 인코더 아웃풋과 디코더 인풋을 그냥 복사해서 연결했더니(stop gradient=sg) 잘 되었다고 함.
(VQ-Diffusion의) 연구진은 둘째 항을 EMA로 대체하는 게 더 잘 작동되어서 그렇게 함.
Vector Quantized Diffusion Model
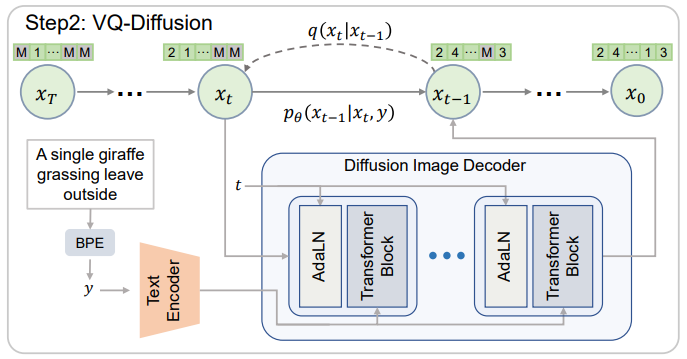
코드북에 매핑된 이미지 토큰 x와 BPE 인코딩을 통해 얻은 텍스트 토큰 y를 통해 conditional transition distribution q(x|y)를 최대화하는 것이 목표이다.
AR 방식 모델들은 소개에 언급한 바와 같은 문제가 있어서 확산 모델을 사용하고, masked language modeling (MLM)에서 영감을 받은 확산 과정과 훈련 방법에 대해 소개함.

Discrete diffusion process
이산 확산 과정은 노이즈를 추가하는 것이 아니라 예를 들면 토큰 일부를 무작위로 교체하는 식으로 진행됨.
또한 역확산을 진행하는 모델은 U-Net이 아니라 트랜스포머 사용.
더 자세히, 이미지 x0의 한 이미지 토큰 x0i에 대해 K x K markov transition matrix Qt를 활용하여 다음 단계에 어떤 토큰으로 바뀔지에 대한 확률을 정의할 수 있다.
(v(x)는 길이가 K고 해당 토큰의 코드북 인덱스만 1인 one-hot 열벡터. 윗첨자 i는 앞으로 생략.)

또한, 마르코프 체인의 특성 때문에 중간단계를 배제하고 0에서 t단계에서의 확률을 바로 도출할 수 있다.

Qt를 보면 그대로 유지될 확률이 조금 더 높고 나머지 인덱스로 대체될 확률은 균일함.

하지만, 확산 과정의 데이터 손상에 균일한 확률을 사용한다는 것은 급격한 의미 변화, 추정 난이도 증가 등 꽤나 불안정한 요소이다.
Mask-and-replace diffusion strategy
위 문제를 해결하기 위해 [MASK] 토큰을 추가한다.
이미지 토큰은 γt의 확률로 마스크 토큰이 되고, 한 번 마스킹되면 이후 단계에서는 변하지 않는다.
Qt는 (K+1)x(K+1) 행렬이 된다.

Mask-and-replace의 이점
- 손상된 토큰이 식별 가능하여 역확산에 용이함.(무작위로 대체된 토큰의 경우 해당 토큰이 대체되었는지 아닌지 알 방법이 없음.)
- 무작위 토큰 대체는 네트워크가 마스크에만 집중하지 않고 전체 context를 이해하도록 장려함.
- 계산 비용 감소. (다음과 같이 닫힌 형태로 계산 가능.)

Learning the reverse process

Reparameterization trick on discrete stage
xt-1을 직접 예측하는 것 보다 다른 대리 변수를 근사화하는 것이 더 좋다.
따라서 모델이 xt-1이 아닌 pθ(x̃0|xt, y)를 추정하도록 하고 xt-1을 구한다.
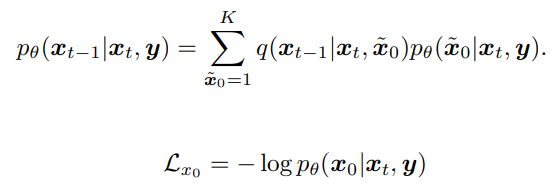
Model architecture
Fast inference strategy
재개매변수화로 인해 모든 추론 단계를 거치지 않고 일정한 보폭으로 단계를 건너뛸 수 있다.
Algorithm

Experiments
256x256 이미지를 32x32 토큰으로(32x32개),
K = 2886,
텍스트 인코더 CLIP,
Timesteps = 100 정도로 작게,
최종 단계에서 마스크 비율은 90%.
'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Null-text Inversion for Editing Real Images using Guided Diffusion Models (0) | 2022.12.30 |
|---|---|
| Prompt-to-Prompt Image Editing with Cross-Attention Control (0) | 2022.12.29 |
| Improved Vector Quantized Diffusion Models (1) | 2022.12.23 |
| Paint by Example: Exemplar-based Image Editing with Diffusion Models (0) | 2022.12.09 |
| Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model (1) | 2022.12.07 |
| Make-A-Video : Text-To-Video Generation Without Text-Video Data (1) | 2022.10.01 |



