재확산을 이용한 이미지 인페인팅
GitHub - andreas128/RePaint: Official PyTorch Code and Models of "RePaint: Inpainting using Denoising Diffusion Probabilistic Mo
Official PyTorch Code and Models of "RePaint: Inpainting using Denoising Diffusion Probabilistic Models", CVPR 2022 - GitHub - andreas128/RePaint: Official PyTorch Code and Models of &quo...
github.com

Abstract
극한의 마스크에도 적용할 수 있는 DDPM 기반 인페인팅 접근 방식인 RePaint를 제안한다. 사전 훈련된 무조건 DDPM을 기반으로 주어진 이미지 정보를 사용하여 마스크되지 않은 영역을 샘플링한다. 원래 네트워크 자체를 수정하지 않고 모든 인페인팅 형식에 대해 고품질의 다양한 출력 이미지를 생성한다.
Preliminaries: Denoising Diffusion Probabilistic Models
순방향 과정

VLB

를 분해한 학습 목표

역방향 과정에서 신경망으로 얻은 분포에 대한 샘플링을 진행하는데 샘플링은 역전파가 불가능하므로 Reparameterization Trick을 이용하여 신경망이 xt-1의 통계값이 아닌 noise를 예측하도록 한다.

DDPM 논문에서는 Lt-1을 단순화한 학습 목표를 사용한다. 이게 더 잘 작동한다고 함.

Improved DDPM에서는 분산을 학습하면 샘플링 단계 수를 줄이는 데 도움이 되는 것을 발견하고 vlb 손실항을 추가함.

원본 이미지를 Gaussian noise로 만드는 순방향 과정을 하나의 수식으로 정리할 수 있다.

이를 통해 훈련 데이터 쌍을 효율적으로 샘플링 가능.
Method
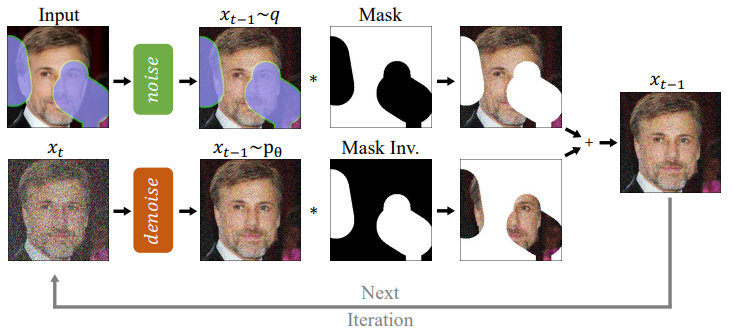
Conditioning on the known Region
사전 훈련된 무조건 DDPM 사용.
알려진 부분은 이미 원본 이미지를 알고 있으므로 다음 공식으로 얻을 수 있음.

마스크 된 부분은 모델에서 샘플링하여 얻음.

합침.

Resampling
위의 방법을 사용하면 content 유형은 비슷하지만 의미적으로 올바르지 못한 이미지가 생성된다.

이러한 문제는 알려진 부분의 샘플링이 마스크된 부분을 고려하지 않기 때문에 발생한다. 각 역방향 단계에서 이미지의 조화를 시도하지만 다음 단계에서 똑같은 문제가 반복되며, 또한 분산의 scheduling으로 인해 후속 단계로 갈수록 조정량이 감소된다.
DDPM은 자연스럽게 일관된 구조를 생성하는데, 이러한 속성을 이용하기 위해 xt-1을 xt로 재확산한다. 새로운 xt는 재확산 이전의 xt에 비해 xt-1unknown의 정보가 일부 보존되어 있다.
같은 작업을 여러 번 반복하면 조화가 점점 더 좋아짐.

점프 단계 j를 사용함. 아래 그림은 10번의 재확산과 점프 단계가 10일 때 확산 시간을 보여준다.

Experiments







클래스 가이딩 결과

점프 단계 ablation




