Diffusion Model + Autoencoder + Cross Attention
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
github.com

Abstract
품질과 유연성을 유지하면서 제한된 계산 리소스에 대한 확산 모델 훈련을 가능하게 하기 위해 사전 훈련된 autoencoder 사용 + cross attention을 도입한 latent diffusion models (LDMs) 제안.
다양한 조건과 인페인팅, 초해상도 등 다양한 작업 가능.
Introduction
확산 모델의 문제점
- 막대한 계산 비용 필요
- 많은 순차적 단계 때문에 훈련된 모델을 평가하는 데도 많은 시간이 소모됨
데이터 공간과 지각적으로 동일한 저차원 표현 공간(더 낮은 차원의 매니폴드에서도 충분히 이미지의 정보를 담을 수 있음)을 제공하는 autoencoder를 훈련하여 더 나은 학습된 잠재 공간에서 확산 모델을 훈련하며 이를 통한 결과 모델 클래스를 LDM(Latent Diffusion Models)이라고 부른다.
이 접근 방식은 장점은 인코딩 단계를 한 번만 훈련하면 여러 다른 확산 모델 훈련에 재사용하거나 완전히 다른 작업에도 사용할 수 있다는 것이다.
본 논문의 기여
- 압축 공간에서 작업하기 때문에 메가픽셀 이미지와 같은 고해상도 합성 가능
- 계산 비용을 크게 낮추며 다양한 작업에서 경쟁력 있는 성능 달성
- 충실한 재구성을 보장하고 잠재 공간의 정규화를 거의 필요로 하지 않음
- Cross attention 기반 범용 컨디셔닝 메커니즘을 설계하여 multi-modal 교육 가능
Method
훈련 단계에서 손실 항을 언더샘플링하여 지각적으로 관련 없는 세부 사항을 무시할 수 있지만 여전히 평가 단계에서 많은 비용이 드므로 생성 학습 단계에서 압축을 명시적으로 분리하여 이러한 단점을 피한다.
이를 위해 autoencoder를 사용하고 이 접근 방식의 장점 :
- 저차원 공간에서 작업하므로 효율적임
- 확산 모델의 귀납적 편향을 여전히 이용
- 학습된 인코더 잠재공간을 다른 작업에 사용할 수 있음
Perceptual Image Compression
지각 압축 모델은 지각 손실, 패치 기반, 적대적 목표의 조합으로 훈련된 autoencoder로 구성된다. 이렇게 하면 L1, L2와 같은 픽셀 기반 손실로 인해 발생하는 흐릿함을 피할 수 있음.
패치 기반 판별자 Dψ가 재구성 이미지 D(E(x))와 원본 이미지를 구별하도록 적대적 방식으로 훈련하고 지각 손실항과 정규화항 추가.

잠재공간 정규화 방법으로는 정규 분포와 비교하여 KL 페널티를 부여하는 KL-reg와 VQGAN과 같이 벡터 양자화를 이용하는 VG-reg 둘 중 하나를 사용함. 재구성 품질을 위해 정규화는 매우 작은 가중치를 적용.
Latent Diffusion Models
일반적인 확산 모델의 목적 함수 :

효율적인 저차원 인코딩 잠재 공간에 접근할 수 있도록 변경 :

신경 백본은 time-conditional UNet(?)으로 구현.

Conditioning Mechanisms
조건 y를 사전 처리하는 도메인 특정 인코더 τθ 도입.
다양한 입력 조건을 반영하기 위해 cross attention 사용.
(ϕi(zt)는 U-Net의 flattened 중간 표현)

목적 함수 :
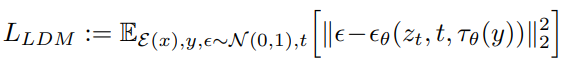
Experiments
텍스트 조건

레이아웃 조건

Semantic map 조건

초해상도

인페인팅




