Cascade 구조를 통해 확산 모델에서 고해상도 샘플 생성

Abstract
Cascade 확산 모델이 샘플 품질을 높이기 위한 보조 이미지 분류기의 도움 없이 충실도가 높은 이미지를 생성할 수 있음을 보여준다. Cascade 확산 모델은 가장 낮은 해상도에서 표준 확산 모델로 시작하여 이미지를 연속적으로 업샘플링하고 더 높은 해상도 세부 사항을 추가하는 하나 이상의 초해상도 확산 모델이 뒤따르는 형태로 다중 확산 모델 파이프라인으로 구성된다.
또한 연구진은 conditioning augmentation이 cascade 모델에서 샘플링하는 동안 복합 오류를 방지하여 cascading pipeline을 훈련하는 데 도움이 된다는 것을 발견했다.
Introduction
Cascading diffusion pipeline을 개선하기 위해 찾은 가장 간단하고 효과적인 기술은 각 초해상도 모델의 컨디셔닝 입력에 강력한 data augmentation를 적용하는 것이다. Conditioning augmentation은 exposure bias라고도 하는 train-test 불일치로 인한 cascading pipeline의 복합 오류를 완화해 고품질 샘플을 생성하는 데 중요하다.
본 논문의 기여는 다음과 같다.
- Cascaded Diffusion Models(CDM) 제안
- Conditioning augmentation : Augmentation에 대한 심층 탐구로 저해상도 업샘플링에서 Gaussian augmentation, 고해상도 업샘플링에서 Gaussian blurring이 핵심 요소임을 찾아냄
Conditioning Augmentation in Cascaded Diffusion Models
고해상도 데이터 x0, 저해상도 데이터 z0.
Cascading pipeline이라는 용어를 생성 모델의 sequence를 참조하는 데 사용.
저해상도의 확산 모델 pθ(z0), 고해상도의 초해상도 확산 모델 pθ(x0|z0).
Cascading pipeline은 고해상도 데이터에 대한 잠재 변수 모델을 형성한다.
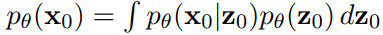
이것을 2개 이상의 해상도로 확장하고 모델 컨디셔닝 pθ(z0|c), pθ(x0|z0,c).
Blurring Augmentation
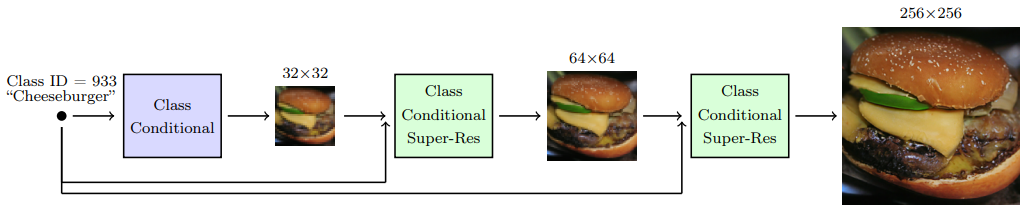
Augmentation의 한 가지 간단한 방법은 blurring이다. 이것이 128x128, 256x256 해상도로 업샘플링하는 데 가장 효과적이었다고 함. 가우시안 필터에 무작위로 적용할 sigma의 범위는 하이퍼 파라미터 검색으로 찾음. 예제의 50%에 적용.
Truncated Conditioning Augmentation
Conditioning augmentation의 한 형태인 truncated conditioning augmentation에 대해 설명한다. 이 방법이 128×128보다 작은 해상도에서 가장 유용하다고 한다.
일반적으로 고해상도 샘플 x0를 생성하려면 저해상도 모델에서 z0를 생성한 다음 초해상도 모델에 입력한다.
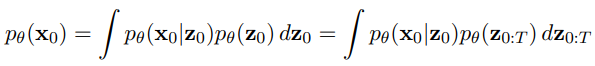
Truncated conditioning augmentation은 저해상도 역 과정을 0이 아닌 시간 단계 s에서 중지하도록 자르는 것을 말한다.

이제 저해상도 모델과 초해상도 모델은 다음과 같고

초해상도 모델의 역 연산은
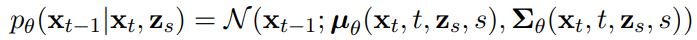
저해상도 역방향 과정을 자르는 것이 augmentation의 한 형태인 이유는 초해상도 모델의 훈련 절차가 noisy z0에 대한 조건화를 포함하기 때문이다.
Truncated conditioning augmentation을 더 정확하게 하기 위해 pθs(x0)에 대한 ELBO 조사.
(ELBO 구하는 부분은 건너뛰어도 상관없음.)
pθs(x0)를 확산 모델 prior(정규 분포), 확산 모델 디코더, 저해상도 및 고해상도 쌍에서 독립적으로 순방향 과정을 실행하는 approximate posterior를 갖는 VAE로 취급할 수 있다.
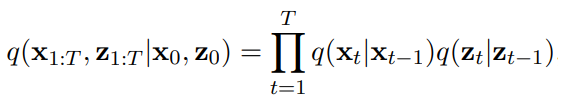
ELBO 구하기


pθ(x0|zs)는 zs를 조건으로 하는 초해상도 모델이므로 이 또한 ELBO를 가진다.
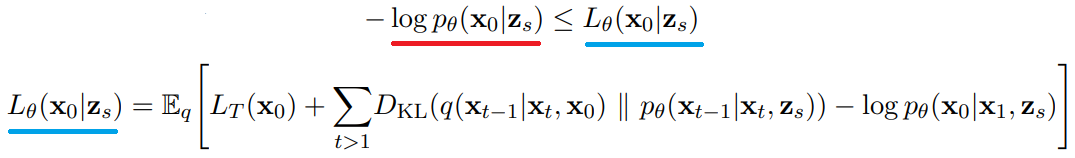
최종적인 ELBO는

저해상도 모델과 고해상도 모델은 별도로 훈련되며 저해상도 모델은 timestep s까지만 훈련하고 이 s를 고해상도 모델은 입력으로 받아 훈련한다.
사실 확산 모델에서 위에서 어렵게 구한 ELBO를 직접 최적화하지는 않는다. 실제 훈련에서는 DDPM의 Lsimple 또는 Improved DDPM의 Lhybrid를 사용한다.
s를 검색할 때는 균일한 무작위 s에 대해 단일 초해상도 모델을 상각(?)하여 모델 재훈련을 방지한다.
임의의 s로 고해상도 모델을 훈련할 때는 저해상도 모델은 고정한다.
2단계 cascading pipeline에 대한 훈련 절차 요약

Non-truncated Conditioning Augmentation
Non-truncated Conditioning Augmentation은 truncated Conditioning Augmentation과 동일한 모델 수정과 훈련 과정을 거친다.
하지만 여기서는 중간에 자르지 않고 z0까지 역방향 과정을 수행한 뒤에 다시 s만큼 순방향 과정을 거쳐 z's를 얻고 초해상도 모델에 공급한다.
Non-truncated Conditioning Augmentation의 이점은 s 검색 단계에서 실용적이라는 것이다.
Truncated Conditioning Augmentation에서는 모든 s값에 대해 샘플 zs를 저장해야 하지만 여기서는 샘플 z0만 저장하면 된다. (순방향 과정은 Gaussian Noise를 더해주기만 하면 되므로)
알고리즘 요약

Experiments





'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models (0) | 2022.09.06 |
|---|---|
| High-Resolution Image Synthesis with Latent Diffusion Models (LDM) (0) | 2022.09.04 |
| Retrieval-Augmented Diffusion Models 논문 리뷰 (1) | 2022.09.02 |
| Pretraining is All You Need for Image-to-Image Translation (PITI) 논문 리뷰 (0) | 2022.08.18 |
| Classifier-Free Diffusion Guidance 논문 리뷰 (0) | 2022.08.16 |
| Diffusion Models Beat GANs on Image Synthesis 논문 리뷰 (0) | 2022.08.15 |



