사용자 입력 페인팅 이미지를 통해 간단히 이미지 편집, 합성 수행

Abstract
불완전한 인간 그림의 manifold에서 사실적인 렌더링에 대한 매핑을 학습하여 기초적인 페인팅 입력에서 "사용자가 그리고 싶어 하는 것"을 예측 및 적응하는 방법을 배우는 새로운 접근 방식 paint2pix를 제안한다.
Introduction
사실적인 이미지를 페인팅 이미지로 바꾸기 위해 agent로 Intelli-Paint 사용.
다음 그림과 같이 paint agent와 paint2pix를 통해 사용자가 점진적으로 원하는 그림을 그려나갈 수 있다.

또한 이미지 생성 외에 편집에도 사용할 수 있으며 섹션 6에서는 사용자 정의 편집이 수행된 이미지에 국한되지 않고 입력 도메인 전체에서 일반화됨을 보여주어 한 이미지에 대한 사용자 정의 편집과 동일한 편집 내용을 의미론적으로 일관된 방식으로 (동일한 입력 도메인에서) 다른 이미지로 전송할 수 있다.
Method

Canvas Encoding Stage
캔버스 인코딩 단계에서는 사용자 그림과 실제 출력 렌더링 간의 매핑을 학습하여 사용자 의도를 예측하는 동시에 점진적 합성 궤적의 수정을 할 수 있도록 하는 것이 목표이다.
현재 캔버스 상태 Ct, 사용자 업데이트 Ct+1, 인코더 E1을 이용하여 초기 잠재 벡터 예측 :
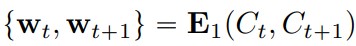
생성기로 현실적인 렌더링 얻기 :

인코더는 훈련에서 해당 과정의 원본 이미지(e.g. FFHQ) ŷt에 대해 다음과 같은 예측 손실로 훈련됨.
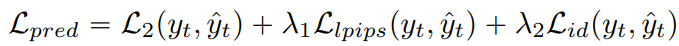
또한 사용자 정의 편집을 반영하기 위한 편집 손실 :
(Ladv는 잠재 공간 예측의 현실성을 보장하기 위한 e4e 잠재 판별자 손실)
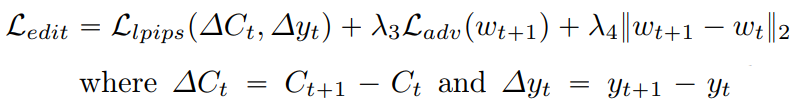
캔버스 인코딩 단계의 최종 손실 함수 :

Identity Embedding Stage
캔버스 인코딩 단계에서 잠재 코드 wt와 wt+1을 가깝게 한 것은 업데이트된 예측 yt+1이 원래 예측 yt에서 파생되도록 하는 데 도움이 되지만 ID의 미묘한 변경으로 불일치가 발생할 수 있다. 따라서 정체성 임베딩 단계에서는 연속적인 이미지 예측 간의 기본 정체성을 유지하여 의미론적 일관성을 보장한다.
인코더 E2는 최종 예측 ỹt+1이 yt의 정체성을 유지하면서 사용자 변경 사항을 반영하도록 한다.

손실 함수 :

(정체성은 yt, 시각적인 부분은 yt+1과 유사하게, 세 번째 항은 ∆t가 wt+1에 최소한의 영향만 주도록 함)

Reason for decoupled encoders
단일 인코더를 사용할 수도 있지만 두 개의 인코더를 사용하는 것에 몇 가지 이점이 있다.
- 첫 번째 인코더에서 ID를 보장하지 않음으로써 사용자 편집으로 ID 변경을 할 수 있다.
- Multi-modal 합성 가능. (중간 과정에 무언가를 추가하기 용이함.)
- 이 섹션에서는 언급되어 있지 않은데 아래 섹션에서 미완성 페인팅 이미지에 대한 출력을 보면 첫 번째 인코더의 역할은 단순 projection이 아니라 입력 페인팅에 대해 출력 값을 '예측' 하는 것으로 보인다. (논문에서 prediction 단어를 몇 번 사용함)
Overall Training
Paint2pix의 최종 손실 :

Ground truth painting annotations
Painting agent로 Intelli-Paint를 사용한 것은 시각적으로 실제 이미지와 가까워서라고 함.
사용자가 그린 그림의 다양한 추상화 정도를 포착하기 위해 연속 캔버스 프레임 {Ct, Ct+1}의 20개 튜플을 균일하게 샘플링하여 입력 캔버스 주석을 수집. 또한 다양한 붓놀림 횟수 {200, 500}에서 페인팅 주석을 수집.
(정확히 어떤 데이터를 어떻게 처리해서 사용했는지, 데이터셋 크기는 어느 정도 인지 등 훈련 데이터셋에 대한 내용이나 인코더 아키텍처에 대한 자세한 내용이 없다. 보충 논문에 대한 언급이 있는 걸로 보아 3일 전 논문이라 아직 보충 논문이 안 나온 듯???)
Inferring Global Edit Directions
사용자 정의 편집은 한 이미지에 국한되지 않고 도메인 전체에 일반화 가능하다. 즉, 한 이미지의 지정 편집에 만족하면 다른 이미지에 대해 새로운 페인팅을 만들 필요 없이 바로 동일한 편집을 적용할 수 있다.
x0 → x1 변환을 다른 이미지 x(with w)에 적용하고 싶다면
(첫째 항 = 편집 방향, 두 번째 항 = x의 ID 보존)

최종 출력 x'

매개변수 α로 강도 조절 가능

다양한 종류의 편집을 간단히 할 수 있는 것이 흥미롭다.
Comparison with Inversion Methods



Multi-modal Synthesis
서로 다른 역할을 하는 두 인코더 덕분에 multi-modal 합성을 할 수 있는데, 예를 들어 ID 보존 역할을 하는 두 번째 인코더에 조건으로 다른 사람의 ID를 사용할 수 있다.

Ablation Study

'논문 리뷰 > GAN' 카테고리의 다른 글
| Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (DragGAN) (1) | 2023.06.10 |
|---|---|
| StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis (1) | 2023.01.27 |
| Sketch Your Own GAN 논문 리뷰 (0) | 2022.08.13 |
| Rewriting a Deep Generative Model 논문 리뷰 (0) | 2022.08.12 |
| Rewriting Geometric Rules of a GAN (GANWarping) 논문 리뷰 (0) | 2022.08.10 |
| Learning to Cartoonize Using White-box Cartoon Representations 논문 리뷰 (0) | 2022.07.13 |



