분류기 없는 가이드로 Inception score와 FID 절충

Abstract
분류기 없이 순수한 생성 모델에 의해 가이드가 실제로 수행될 수 있음을 보여준다. Classifier-free guidance로 조건부 및 무조건 모델을 공동으로 훈련하고 결과 점수 추정치를 결합하여 샘플 품질과 다양성 간의 균형을 달성한다.
Introduction
분류기 지침에 대한 이전의 연구는 확산 모델의 점수 추정치를 분류기의 gradient와 혼합했다. Gradient의 강도를 변경하여 Inception score와 FID 점수를 절충할 수 있다.
하지만 분류기 지침은 모델 파이프라인을 복잡하게 만들고 노이즈가 있는 데이터에 대해 훈련해야 하므로 사전 훈련된 분류기를 사용할 수 없다. 또한 분류기의 gradient 방향으로 나아가는 것이 적대적 공격으로 간주될 수 있으며 GAN과 유사하고 특히 비모수 생성기와 유사하다고 한다.
이를 해결하기 위해 분류기 없는 가이드를 제시한다. 이는 조건부 및 무조건 확산 모델을 공동으로 훈련하고 점수 추정치를 혼합함으로써 FID/IS trade-off를 달성한다. 매우 충실도 높은 이미지 생성 가능.
Background
(Variational diffusion models의 연속 시간 확산 모델에 대해서 이미 잘 알면 다음 섹션으로)
SNR 값을 step으로 사용함.
연속 시간에서 확산 모델 훈련( x ∼ p(x), z = {zλ | λ ∈ [λmin, λmax]} ).
(zλ에서의 로그 신호 대 잡음비 λ = log αλ2 /σλ2, 순방향 과정 q에서는 λ가 점점 감소함.)

x를 조건으로 하는 역방향 과정
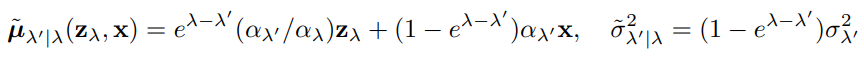

생성 모델 xθ을 이용한 역방향 과정 (zλmin = N(0,I) 에서 시작)

λmin ~ λmax에서 T번의 timestep 진행, 재 매개변수화 트릭으로 샘플 얻을 수 있음, 연속 공간의 모델 분산을 pθ(z)로 표기, v는 무한하지 않은 시간 단계에서만 효과 있기 때문에 하이퍼 피라미터로 대체.
모델 매개변수화 ( εθ(zλ, λ) → εθ(zλ) 표기 단순화 )

목적 함수

λ는 분포 p(λ)에서 가져옴.
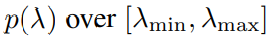
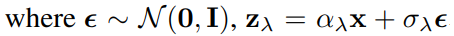
위 목적함수는 multiple noise scale에 대한 denoising score matching이며
p(λ)가 균일할 때는 모델의 로그 우도에 대한 VLB(variational lower bound)에 비례한다.
p(λ)가 균일하지 않으면 가중치가 부여된 VLB로 해석할 수 있다. (참조 : cosine schedule)
εθ(zλ)의 손실은 denoising score matching이기 때문에
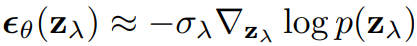
Guidance
별도의 분류기 없이 FID/IS trade-off를 할 수 있는 방법을 제시한다.
Classifier Guidance
분류기 지침에서는 확산 점수가 분류기의 gradient를 포함하도록 수정된다.
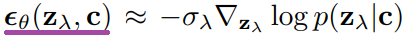

w는 올바른 label에 높은 가능성을 할당하는 데이터의 확률에 가중치를 부여하여 FID/IS trade-off를 달성한다.

분류기 지침은 각 class에 대해 확률분포의 평균을 이동시킴.

Classifier-Free Guidance
조건부 모델의 클래스에 null 토큰을 입력함으로써 간단히 무조건 모델로 만들 수 있다.

확률적으로 null 토큰을 입력하여 하나의 모델로 조건부와 무조건의 경우를 공동으로 훈련한다.
(따로 훈련해도 되지만 이 쪽이 훨씬 더 효율적이고 별 차이 없었나 봄.)
조건부 및 무조건 점수 추정치의 선형 조합을 사용하여 샘플링 수행.
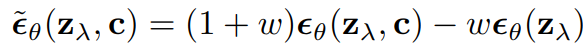
Discussion
- 분류기 없는 가이드의 가장 실용적인 이점은 극도의 단순성이다. 훈련 중에는 확률적으로 null 토큰을 입력하고 샘플링 중에는 점수 추정치를 혼합하는 몇 줄의 코드만 추가하면 된다. 분류기 지침은 추가 분류기를 훈련해야 하므로 훈련 파이프라인을 복잡하게 만든다.
- 분류기 없이도 FID/IS trade-off를 달성했다.
- 분류기는 확률 밀도 자체를 매개변수화 한 모델이지만 확산 모델은 밀도의 score를 직접 매개변수화 한 모델이다. 이러한 unconstrained score model은 분류기 gradient와 달리 점수 추정치가 보존 벡터장을 형성하지 않아도 된다. 따라서 분류기 지침 확산 모델은 모델과 유사하지 않은 step 방향으로 모델에 대한 적대적 공격으로 해석될 수 있으나 분류기 없는 확산 모델은 단일 모델에서 이미지가 생성된다.
- 단점은 샘플링 속도이다. 분류기 없는 확산 모델의 경우 점수 혼합을 위해 전진 path를 두 번 시행해야 하지만 분류기는 생성 모델에 비해 속도가 빠르다.
Experiments

왼쪽 3줄 : 가이드 없는 샘플
오른쪽 3줄 : 분류기 없는 가이드(w = 3.0)로 생성된 샘플


'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models (0) | 2022.09.06 |
|---|---|
| High-Resolution Image Synthesis with Latent Diffusion Models (LDM) (0) | 2022.09.04 |
| Retrieval-Augmented Diffusion Models 논문 리뷰 (0) | 2022.09.02 |
| Cascaded Diffusion Models for High Fidelity Image Generation 논문 리뷰 (0) | 2022.08.18 |
| Pretraining is All You Need for Image-to-Image Translation (PITI) 논문 리뷰 (0) | 2022.08.18 |
| Diffusion Models Beat GANs on Image Synthesis 논문 리뷰 (0) | 2022.08.15 |



