FastGAN은 2021년 1월에 나온 논문인데 내가 한동안 써봤던 Projected GAN에서 기본 설정이었던 모델이었다. 그때는 FastGAN 논문도 안 읽어보고 그냥 썼는데 최신 논문 중에 내가 좋아하는 생성 모델은 별로 없고 딱히 재밌어 보이는 것도 없어서 한 번 정독해 보기로 했다. 그리고 나중에 StyleGAN-XL 논문도 리뷰할 예정인데 거기서 Projected GAN을 사용했기 때문에 Projected GAN 논문을 리뷰할 예정이고 그러면 또 거기서도 FastGAN이 언급되니까...
아무튼 FastGAN-Projected GAN-StyleGAN XL 순으로 논문 리뷰를 할 예정이다.
FastGAN Github Paper(arxiv)


Abstract
GAN을 훈련하려면 일반적으로 일반적으로 높은 컴퓨팅 비용과 방대한 수의 훈련 이미지가 필요하다. 본 논문에서는 최소한의 컴퓨팅 비용으로 GAN에 대한 few-shot 이미지 합성 작업을 연구하고 1024 × 1024 해상도에서 우수한 품질을 얻는 경량 GAN 구조를 제안한다. 특히 FastGAN은 단일 GPU에서 몇 시간만 훈련하면 처음부터 수렴되며 100개 미만의 훈련 샘플로도 일관된 성능을 갖는다. 이 작업의 기술 설계는 skip-layer channel-wise excitation 모듈과 feature-encoder로 훈련된 자체 감독 판별기로 구성되어 있다. 다양한 이미지 도메인을 포함하는 13개의 데이터 세트를 사용하여 StyleGAN2와 비교해 우수한 성능을 보여준다.
Introduction
GAN은 많은 응용 분야에서 큰 잠재력을 보여주지만 요구되는 값비싼 컴퓨팅 비용과 방대한 양의 필수 교육 데이터가 이를 제한한다. 본 논문의 목표는 낮은 계산 비용과 적은 훈련 샘플로 고해상도 이미지에 대한 무조건적인 GAN을 훈련하는 것이다. 이러한 까다로운 훈련 조건에서 GAN을 훈련시키기 위해서는 빠르게 학습할 수 있는 생성기 G와 G를 훈련시키는 데 유용한 신호를 지속적으로 제공할 수 있는 판별기 D가 필요하다.
본 논문의 기여는 다음과 같다.
- 대규모 feature 맵에서 채널 응답을 수정하기 위해 저규모 활성화를 활용하는 SLE(Skip-Layer channel-wise excitation) 모듈을 설계한다. SLE는 모델 가중치 전반에 걸쳐 보다 강력한 gradient 흐름을 허용하여 더 빠른 교육을 제공한다.
- 추가 디코더가 있는 feature 인코더로 훈련된 자체 감독 판별기 D를 제안한다. D가 입력 이미지에서 더 많은 영역을 포함하는 더 설명적인 feature 맵을 학습하도록 강제하여 G를 훈련하기 위한 더 포괄적인 신호를 생성한다. D에 대한 여러 자체 감독 전략을 테스트하는데, 그 중에서 오토인코딩이 가장 잘 작동한다는 것을 보여준다.
- 제안된 두 가지 기법을 기반으로 계산 효율적인 GAN 모델을 구축하고, 여러 개의 데이터 세트에서 모델의 견고성을 보여준다.
Method
FastGAN은 미니멀리즘 디자인을 채택한다. 특히, 각 해상도에서 단일 컨볼루션 계층을 사용하고 G와 D 모두에서 고해상도(512x512 이상) 컨볼루션에 대해 3개의 채널만 적용한다. 이러한 설계는 FastGAN을 SOTA 모델보다 훨씬 작고 훈련 속도도 빠르게 한다.
Skip-Layer Channel-Wise Excitation
고해상도 이미지를 합성하기 위해, 생성기는 필연적으로 더 많은 컨볼루션 레이어를 사용하여 더 깊어져야 한다. 더 많은 컨볼루션 레이어를 가진 더 깊은 모델은 매개 변수의 수가 증가하고 G를 통한 더 약한 gradient 흐름으로 인해 훈련 시간이 길어진다. 심층 모델을 더 잘 훈련시키기 위해 skip-connection을 사용하여 레이어 간의 gradient 신호를 강화하는 잔차 구조(ResBlock)가 제안되었다.

연구진은 두 가지 고유한 설계로 skip-connection 아이디어를 SLE로 재구성한다.
- FastGAN에서는 skip-connection을 채널별 곱셈으로 적용하여 컨볼루션의 무거운 계산을 제거한다.
- 기존의 skip-connection은 동일 해상도 내에서만 사용되었지만 SLE에서는 동일한 공간 차원이 필요하지 않기 때문에 훨씬 더 다양한 해상도 간에 skip-connection을 수행한다.
이 두 가지 설계는 SLE가 추가 계산 부담 없이 ResBlock의 장점인 shortcut gradient 흐름을 계승하도록 한다.
먼저, 낮은 해상도 이미지 xlow와 높은 해상도 이미지 xhigh가 주어지면 풀링과 컨볼루션을 통해 1x1xC 형태로 만들고 non-linearity를 적용한 뒤 1x1 컨볼루션으로 xhigh와 같은 채널수를 가지게 한다. 그리고 시그모이드 적용 후 xhigh에 채널별 곱셈을 한다.
Squeeze-and-Excitation 모듈과 부분적으로 유사하지만 SLE는 서로 다른 출처의 feature 맵끼리 연산한다는 점에서 다르며, SE의 채널별 feature 재보정의 이점과 ResBlock의 gradient 흐름 강화의 이점 모두를 챙길 수 있다.
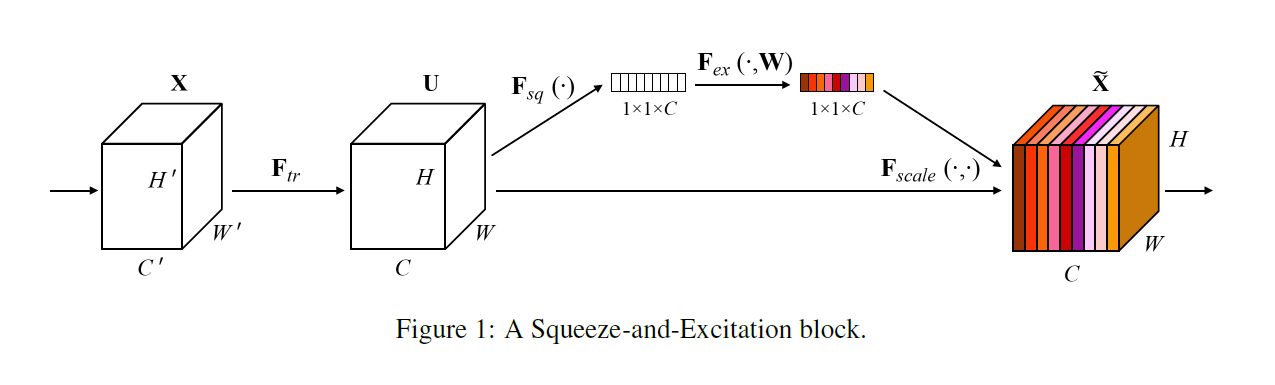
또한 content와 스타일을 분리하는 인스턴스 정규화와도 비슷한 효과를 내는데, 낮은 레이어와 높은 레이어에서 주목하는 feature가 다르기 때문에 SLE에서 xlow를 바꾸는 것으로 xhigh의 content를 유지한 채 스타일을 바꿀 수 있다.
Self-Supervised Discriminator
D에 대한 강력한 정규화를 제공하는 본 논문의 접근 방식은 놀라울 정도로 간단하다. D를 인코더로 취급하고 작은 디코더로 훈련한다. 이러한 오토인코딩 훈련은 디코더가 좋은 재구성을 제공할 수 있는 이미지 feature를 인코더 D가 추출하도록 강제한다. 디코더는 실제 샘플에 대해서만 훈련되는 간단한 재구성 손실에 대해 D와 함께 최적화된다. (후술함)

자체 감독 판별기의 아키텍처는 다음과 같다.

162의 해상도 f1과 82의 해상도 f2에 대해 같은 두 개의 디코더를 사용한다. 디코더는 4개의 컨볼루션 계층으로 이루어져 있고 128x128 이미지를 생성한다.
f1을 가로세로 크기의 1/8만큼(1/2이어야 크기가 맞는데 오타인지 모르겠다...) crop하고 디코더를 통과시켜 I'part 를 구하고 f2를 디코더에 통과시켜 I'를 얻는다.
그리고 실제 이미지를 다운샘플링하고 I'part와 같은 부분을 crop하여 I, Ipart를 얻고 매칭하여 손실을 계산한다.
이러한 재구성 훈련은 D가 입력에서 전체 구성(f2)과 세부 텍스처(f1)를 모두 포함하는 보다 포괄적인 표현을 추출하도록 한다. Crop 말고도, 더 나은 성능을 위해 더 많은 연산을 탐구할 수 있다.
D에 대한 자체 감독 전략은 오토인코더의 형태로 제공되지만, 이 접근 방식은 GAN과 오토인코더를 결합하려는 작업과는 근본적으로 다르며, FastGAN은 훨씬 단순한 훈련 스키마를 가진 순수한 GAN이다. 인코딩 훈련은 단지 D를 정규화하기 위한 것이다. 디코더 연산은 정규화의 측면에서 다른 정규화 방법들보다 훨씬 적은 추가비용을 요구한다.
전체 손실 계산으로는 hinge 손실이 가장 빠르게 계산된다는 것을 발견했기 때문에 적대적 손실의 hinge 버전을 사용한다.
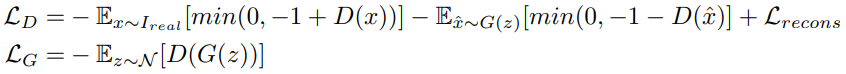
(그냥 힌지 손실에 재구성 손실 더한거임.)
Conclusion
본 논문에서는 100개 이하의 높은 충실도 이미지와 제한된 컴퓨팅 리소스를 고려할 때 향상된 합성 품질로 GAN 훈련을 안정화시키는 두 가지 기술을 소개한다. 다양한 콘텐츠 변형이 있는 13개의 데이터 세트에서, Skip-Layer Channel-Wise Excitation 모듈과 판별기에 대한 자체 감독 정규화가 GAN의 합성 성능을 크게 향상시킨다는 것을 보여준다.
Experiment
내가 써본 모델이고, FastGAN은 완성도 보다는 매우 작은 데이터셋에서 빠른 수렴 속도와 적은 컴퓨팅 비용에 강점이 있기 때문에 솔직히 정량적 평가는 의미 없다고 생각된다. 딱히 비교할 모델이 없기도 하다.
이미지 보간

스타일 믹싱

StyleGAN2와의 비교


'논문 리뷰 > GAN' 카테고리의 다른 글
| Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning (CAST) 논문 리뷰 (0) | 2022.05.26 |
|---|---|
| StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets 논문 리뷰 (2) | 2022.05.14 |
| Projected GANs Converge Faster 논문 리뷰 (0) | 2022.05.14 |
| DualStyleGAN 논문 리뷰 (0) | 2022.03.28 |
| Alias-Free GAN (StyleGAN3) 리뷰 - Architecture (0) | 2022.03.26 |
| Alias-Free GAN (StyleGAN3) 리뷰 - 개념 (2) | 2022.03.09 |



