Generator-Discriminator Framework를 통해 일반화 능력을 크게 향상할 수 있는 instruction dataset 제작
[arXiv](Current version v2)
Abstract
Instruction tuning 방법은 중복 데이터를 생성하는 경우가 많으며 데이터 품질을 충분히 제어할 수 없다.
4개의 범용 코드 관련 작업에 걸쳐 20k의 instruction instance로 구성된 데이터셋인 CodeOcean을 소개하고 새로운 fine-tuned Code LLM인 WaveCoder를 제안한다.
CodeOcean: Four-task Code-related Instruction Data
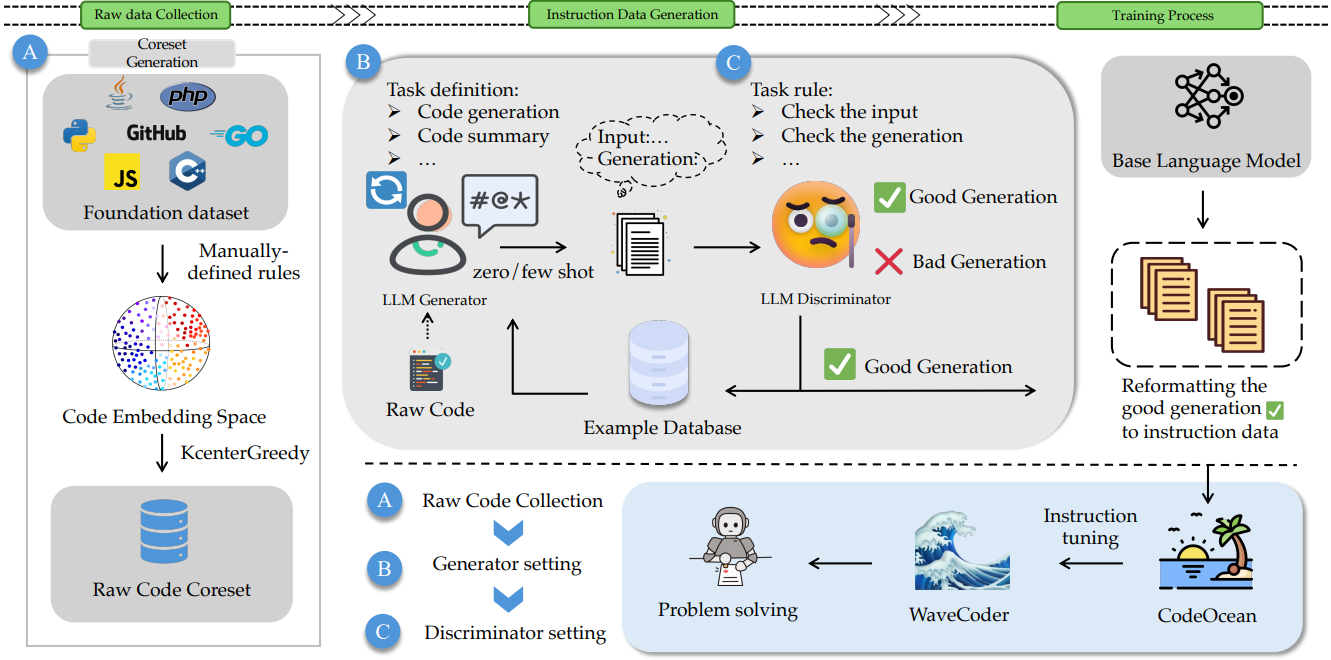
Tasks Setting
코드와 관련된 가장 보편적인 4가지 작업 선택:
- Code Summarization (code-to-text)
- Code Generation (text-to-code, code-to-code)
- Code Translation (code-to-code) : 다른 프로그래밍 언어로 번역
- Code Repair (code-to-code)
Generation of Training Data
과거 연구에서 많은 연구자들은 instruction tuning에서 데이터의 양보다는 품질과 다양성이 성능에 직접적인 관련이 있다는 것을 발견했다.
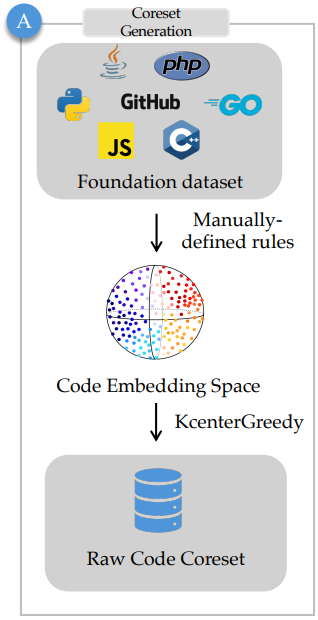
Selection of Raw Code
CodeSearchNet dataset에서 저품질 코드 필터링:
- 길이가 50보다 작거나 800보다 큰 코드 제거
- Code Alpaca에 따라 blacklist words가 포함된 코드 제거
필터링 후 데이터셋 크기는 120만 개로 여전히 많다.
사전 훈련된 언어 모델(roberta-large)을 통해 원시 코드를 인코딩하고 KCenterGreedy 알고리즘을 적용하여 다양성을 극대화한 핵심 샘플 세트를 얻는다.
LLM-based Generator-Discriminator Framework
광범위한 unsupervised open source code를 활용하여 supervised instruction data를 생성할 수 있는 새로운 LLM 기반 Generator-Discriminator Framework를 제안한다.
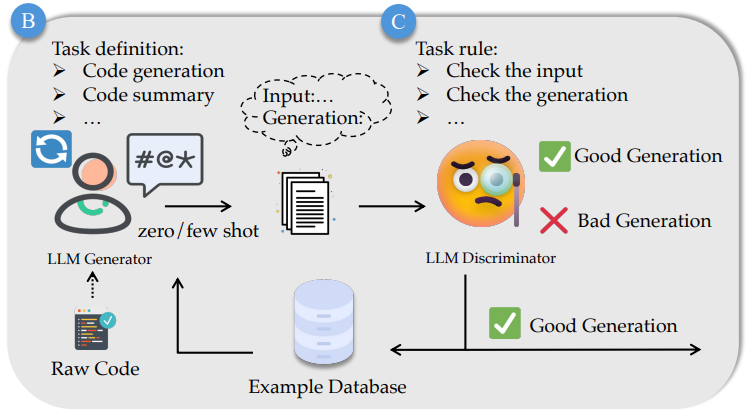
Generation phase : GPT-4를 활용하여 특정 시나리오에서의 작업과 작업에 대한 생성 요구사항 정의. 또한 입력 원시 코드와 좋은 사례, 나쁜 사례에 대해 GPT-3.5의 few-shot 기능을 활용하여 instruction tuning에 필요한 지식과 정보를 생성한다.
좋은 사례와 나쁜 사례를 few-shot으로 제공하여 더 좋은 instruction instance를 생성하도록 한다는 뜻인 듯.
Discriminator phase : GPT-4는 instruction instance의 품질을 평가하여 좋은 사례와 나쁜 사례로 분류하고 이 정보는 다음 세대에서 재활용된다.
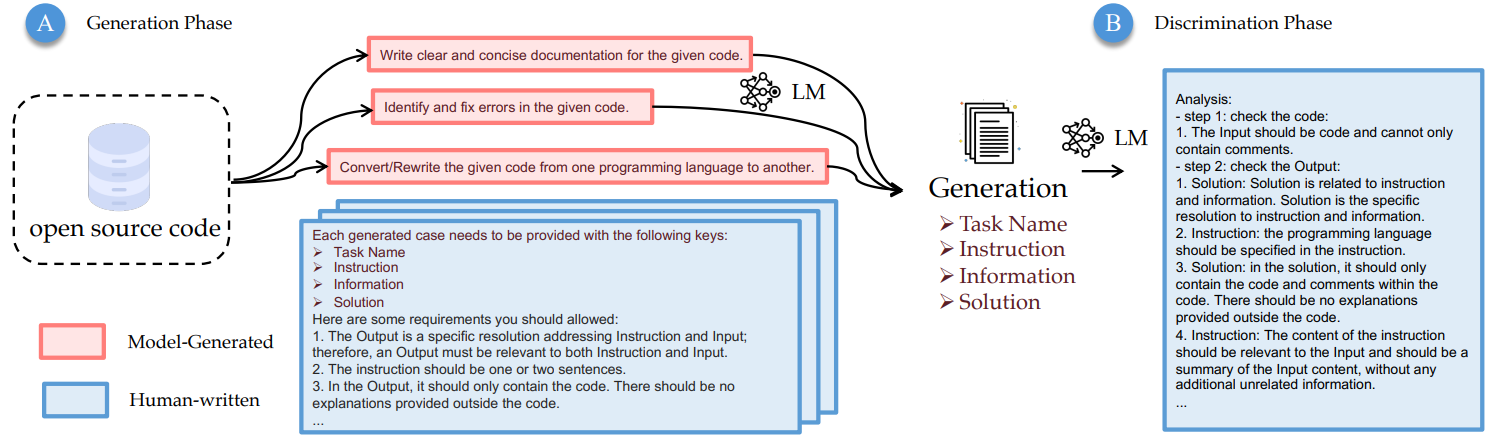
예시 : 원시 코드 (a), 생성기 출력 (b), 판별기의 분석 (c)

Training
훈련은 위의 과정을 통해 생성된 20k 데이터셋과 추가적인 논리 데이터셋에 의존한다.
다음과 같은 prompt를 통해 사전 훈련된 LLM을 fine-tuning 한다.

Experiments 생략.



