Weighted likeihood를 통해 online fine-tuning 개선
강화학습 하나도 몰라서 힘들었다...
[Github]
[arXiv](Current version v6)
I. Introduction
Offline data를 통한 사전 훈련과 online data 수집을 통한 정책 개선을 연결하기 위해 weighted maximum likeihood를 사용한 Advantage Weighted Actor Critic (AWAC) 알고리즘을 제안한다.

II. Preliminaries
Key concepts in Reinforcement Learning
REINFORCE — a policy-gradient based reinforcement Learning algorithm
Q-learning: a value-based reinforcement learning algorithm
The Actor-Critic Reinforcement Learning algorithm
Baseline function을 빼면 gradient의 분산이 줄어드는 이유:
예를 들어, 아주 가끔씩만 큰 보상을 얻을 수 있는 상황의 경우 보상 rt는

하지만 기준선으로 Vπ(s)를 뺄 경우 '보상에 대한 gradient'가 아니라 '현재 행동이 정책을 따를 때에 비해서 얼마나 이점을 얻었느냐'에 대한 gradient가 된다. (참고)

actor-critic algorithm:


정리하면 actor-critic algorithm은 policy gradient update에서 baseline function으로 critic network를 사용하는 것이다.







인간 시대의 끝이 도래했다
state s, action a, policy π(a|s), rewards r(s,a), dynamics p(s'| s,a), discounted return Rt.
Agent의 목표는 policy를 통해 discounted return을 최대화하는 것이다.

최적의 policy는 gradient ∇J(π)를 통해 직접 학습할 수 있지만 넓은 action space, state space로 인해 종종 효과적이지 않다.
이에 대해 많은 알고리즘은 advantage function A를 사용하여 분산을 줄이려고 한다.

Actor-critic algorithm:


Critic(Q-function)의 업데이트:
Actor-critic algorithm에서 critic은 가치 함수 Vπ(s)(정책 π를 따르는 agent의 상태가 s일 때의 기댓값)를 추정하지만 본 논문에서는 정책 외 데이터를 다루기 위해 Q-function estimator를 critic으로 사용한다.

Actor의 업데이트:

III. Challenges in Offline RL with Online Fine-Tuning
Problem Definition
Offline dataset D = {(s, a, s', r)}가 주어지면 D를 통해 사전 훈련하고 소량의 online 상호 작용을 통해 최적의 정책을 학습하는 것이 목표.

Data Efficiency
두 가지 문제:
- Offline data가 최적이 아닐 수 있음
- Online fine-tuning은 이전 데이터를 재사용하지 않으므로 비효율적
다음 그림에서 알 수 있듯이 on-policy 방법은 매우 느리다.

Bootstrap Error in Offline Learning with Actor-Critic Methods
Soft actor-critic과 같은 off-policy actor-critic algorithm은 정책 외 행동에 대한 bootstrapping 오류가 누적되어 성능 감소가 나타난다.

일부 offline algorithm에서는 지금까지 본 모든 데이터(offline+online data)에 대한 분포 πβ와 관련된 제약 조건을 추가하여 이러한 문제를 해결한다.

Excessively Conservative Online Learning
제약 조건이 있는 offline RL algorithm인 BEAR은 offline에서는 좋은 성능을 발휘하지만 online fine-tuning 시(-loose) 어려움을 겪는다.
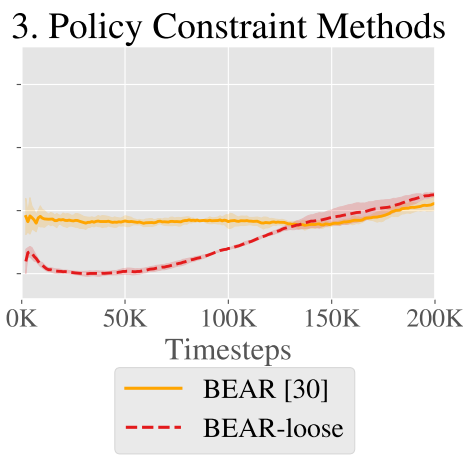
Online update는 offline data와 online data의 다중 모드 행동 분포로 인해 더 어렵다.
아래 그림을 보면 online fine-tuning 시작 시 log likeihood가 감소함을 볼 수 있다.

IV. Advantage Weighted Actor Critic: A Simple Algorithm for Fine-Tuning from Offine Datasets
AWAC(Advantage Weighted Actor-Critic)에는 Qπ를 학습하는 정책 평가 단계와 π를 업데이트하는 정책 개선 단계가 있다.
정책 개선 단계에서는 원래처럼 Q-function을 최대화함과 동시에 KL-divergence 제약 조건 추가.

하지만 위에서 보았듯이 명시적인 행동 모델에 제약을 적용하는 방법은 성능을 떨어트린다. 대신에 Lagrangian을 사용하여 non-parametric closed form으로 암묵적으로 제약을 적용한다.

이 문제에 대한 닫힌 형태의 해는 다음과 같다. (advantage를 지수화, 참고)

신경망과 같은 함수 근사기를 사용할 때, non-parametric solution을 정책 공간에 투영해야 한다.
피라미터 θ를 가진 정책 πθ의 경우, 이는 데이터 분포 pπβ(s) 아래에서 πθ와 π*의 KL divergence를 최소화하는 것으로 수행된다.

정책 업데이트는 다음과 같이 weighted maximum likelihood를 계산한다.

실제로는 정규화 상수 Z가 있지만

단순화된 버전이 더 성능이 좋았다고 한다.

Avoiding explicit behavior modeling
행동에 대한 가치를 명시적으로 모델링하지 않고 likeihood를 사용하여 지나치게 보수적인 업데이트를 방지하고 online fine-tuning 중에 새로운 데이터를 더 잘 통합한다.
Policy evaluation
단일 action (s, a, s', r) ∼ β 형식의 데이터를 다루기 때문에 정책 평가와 개선이 같은 주기로 이루어지는 것으로 보인다.

'논문 리뷰 > etc.' 카테고리의 다른 글
| Layered Neural Atlases for Consistent Video Editing (2) | 2023.12.07 |
|---|---|
| CLIPasso: Semantically-Aware Object Sketching (3) | 2023.12.05 |
| Fast Feedforward Networks (FFF) (2) | 2023.11.27 |
| Memory-Efficient Pipeline-Parallel DNN Training (PipeDream-2BW, PipeDream-Flush) (1) | 2023.11.10 |
| PipeDream: Fast and Efficient Pipeline Parallel DNN Training (0) | 2023.11.10 |
| GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism (0) | 2023.11.09 |



