Text-to-image 모델에 모듈을 추가하여 비디오 생성
 |
|
|
|
Abstract
Motion modeling module을 통해 T2I 모델에서 애니메이션을 생성하는 AnimateDiff 제안
Personalized Animation
다음 그림과 같이 개인화된 T2I 모델에 바로 삽입하여 사용할 수 있는 모듈을 목표로 한다.
Motion Modeling Module
Network Inflation
프레임 시간축이 추가된 5D(b*c*f*h*w) 텐서를 처리하기 위해 video diffusion model과 같이 원본 U-Net의 2D convolution과 attention layer를 Pseudo-3D layer로 교체하고 공간축을 따라 작동하도록 한다.
MMM에서는 시간축을 따라 self-attention 수행.

Module Design
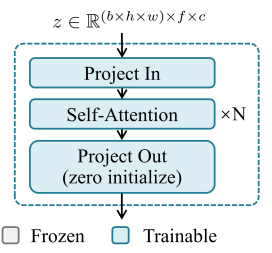
MMM의 설계로 시간축 attention block이 있는 vanilla temporal transformer 채택.
시간 위치를 알 수 있도록 self-attention block에 위치 인코딩 추가.
모든 해상도에 MMM 삽입.

ControlNet과 같이 출력 계층의 모든 가중치와 편향을 0으로 초기화.
Training Objective
훈련은 LDM(stable diffusion)과 똑같음.
샘플링된 비디오에서 각 프레임에 대해 다음 손실함수를 최적화(MMM만 훈련됨):