데이터셋이 문제라는 것을 깨닫고 새로운 대책을 생각해 냈는데, 기존 데이터셋과 비슷하지만 다른 데이터셋을 가짜로 판단하도록 판별자를 학습시키는 것이다.

저번의 글에서 GAN는 생성 이미지의 확률분포와 목표 데이터셋의 확률 분포를 근사시키는 것이라고 했었다.
위 이미지의 진한 회색의 안쪽으로 근사될수록 더 진짜같은 이미지를 생성해 내는 것이다.
지금 내 데이터셋이 질이 좋지 않아 공간 자체가 모호한 상황이고 그래서 학습이 진행되지 않는다. 실제 latent vector는 단순한 2차원이 아닌 훨씬 고차원이기 때문에 쉽게 근사시키기가 힘들다.
다른 데이터셋을 가짜로 판단하도록 학습시킨다는 게 무슨 뜻이냐면

분포 내부에 대한 정보(실제 데이터셋) 뿐만 아니라 바깥에 대한 정보를 줌으로써 확률분포 공간의 경계에 대한 모호함?을 해소한다는 전략이다.
근데... 그렇게 해서 학습을 해봤는데도 안되더라... 결국 이런저런 시도를 해봤자 데이터셋의 근본적인 문제를 해결 할 수는 없었다. 요즘 시대에 빅데이터가 괜히 중요하다 중요하다 하는게 아니다...
쨋든 하던 건 접고 목표 데이터셋과 다른 데이터셋을 그냥 합쳐서 마지막으로 돌려놓고 잠을 잤다.
(다른 데이터셋도 실제 이미지가 아닌 목표 데이터셋과 유사한 그림 이미지이기 때문에 GAN가 특정 확률분포를 인식 할 수 있을거라고 생각했음.)
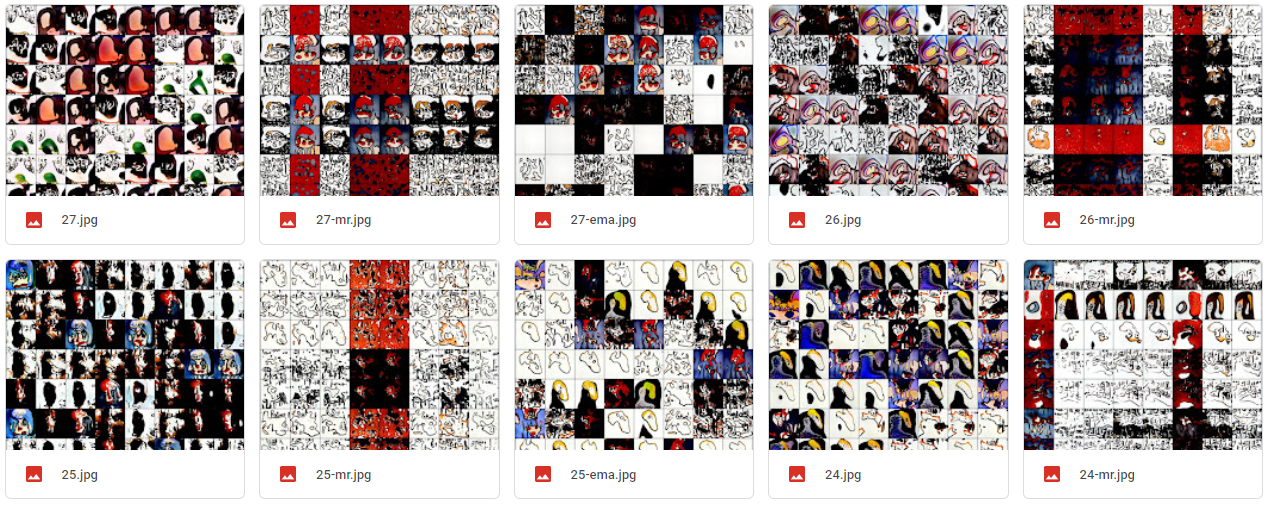
대충 다 섞고 돌린거라 일관성은 없지만 확실히 다양한 이미지가 생성되는 모습
후기)
초기 목표를 성공하진 못했지만 GAN에 대해서 많이 알 수 있었던 시간이었다. 이전 글을 쓰면서도 언급 했었던 것 같은데 내가 이런 복잡한 모델을 다루는 것이 처음이라 뭔가 하나를 해결하는 데 오래 걸렸다. 그냥 물어보면 금방인 걸 몇시간 동안 인터넷을 뒤지며 여러가지 문제들을 해결해왔다.
하지만 그 시간들이 시간 낭비는 아닌 게, 어차피 알아야 할 것들이고 뭐 레딧, 깃헙, 스택오버플로우, 파이토치 포럼 등등 많은 곳을 오가며 다양한 정보를 많이 얻었다. 처음 목표는 styleGAN2 간소화 모델을 통해서 그림 이미지를 생성해 보는 것 이었는데, 하다보니 ADA도 결국 쓰게 되고, ADA를 기존 모델에 이식하기 위해 복잡해서 손대기 싫었던 공식 코드를 다 뜯어보기도 했다. 다른 사람들의 모델도 보고 비교하면서 이사람은 이렇게 저사람은 저렇게 하는구나 싶었고, 여러가지 피라미터들을 시험해봤고, 결국엔 대충 구동만 시켜보자 했던 것이 GAN의 A to Z를 알게 되었다.
데이터셋이 엄청나게 중요하다... 워낙 GAN이 학습 시키기가 어렵고, 정량적 평가도 거의 불가능해 사람이 생성이미지를 보고 모델의 성능을 판단해야한다. 게다가 학습시간도 엄청나게 오래걸리고 컴퓨팅 파워도 많이 필요해서 뭔가 연습용으로 좋지 않은 것 같다.
하지만 뭔가 낭만이 있달까.. 인간은 창조하는 것을 좋아하지 않는가? 물체 감지나 언어모델 같은 다른 모델들은 뭔가 결과가 눈에 딱딱 보이는 그런 임팩트가 없는 느낌.. 무에서 유를 창조하는, GAN야 말로 기계가 갖기 힘든 낭만이 아닐까...
마지막은 일론 머스크의 한마디
Work Super Hard!
'Deep Learning > GAN' 카테고리의 다른 글
| Projected GAN 1 (0) | 2021.12.06 |
|---|---|
| styleGAN 학습을 위한 여정 7 - 진짜 끝 (0) | 2021.12.01 |
| styleGAN 학습을 위한 여정 6 (0) | 2021.11.30 |
| styleGAN 학습을 위한 여정 4 (0) | 2021.11.04 |
| styleGAN 학습을 위한 여정 3 (0) | 2021.11.03 |
| styleGAN 학습을 위한 여정 2 (0) | 2021.10.31 |



